

- デザイン評価
- 棚画像ヒートマップ
- デザイン生成
- ネーミング・
キャッチコピー生成 - キービジュアル作成
function 01評価対象の国の選択
- 2023年11月現在、日本・中国・タイ・インドネシアの4ヵ国を対象としたデザイン評価が可能です。
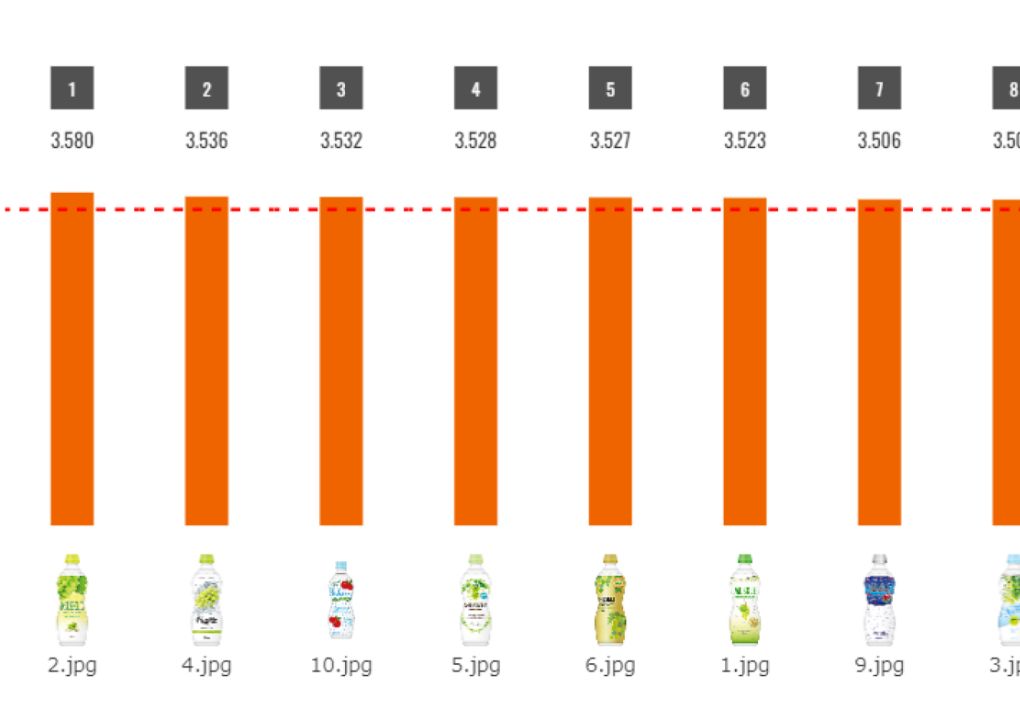
function 02好意度スコア
-
パッケージデザインの好意度スコアを最大5(好き)から最小1(好きではない)までの加重平均値で予測します。全体、男性・女性、年代別(20代/30代/40代/50代)、性別×年代別の計15のセグメントで算出できます。画面上にグラフや数表で表示されます。3つの基準値(基準値/過去プロジェクト/自由設定)を設定でき、その基準値を上回っているか一目でわかります。PDF、CSVで保存ができます。
※精度についてはこちら
function 03ヒートマップ
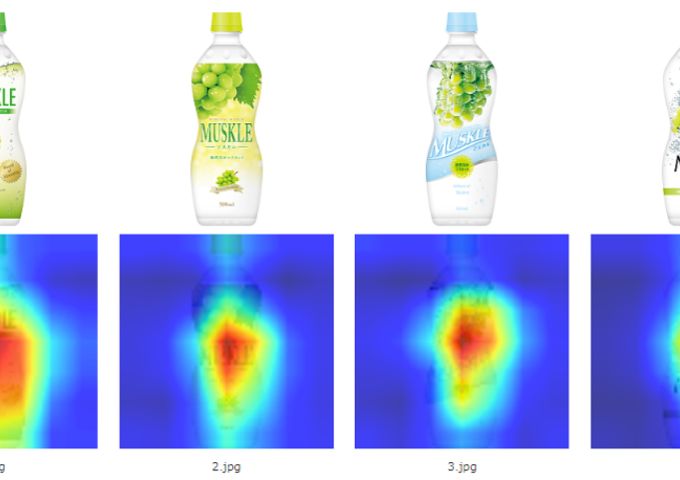
- パッケージデザインのどの部分が印象に残るかを可視化します。印象に残る割合が高いほど赤く、少ないほど青くなるように表示しています。デザインを修正するうえで重要な指針となります。結果はPDFで保存できます。
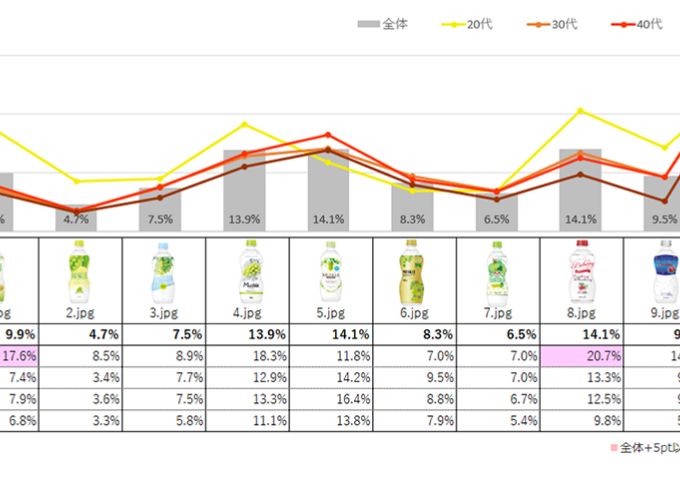
function 04イメージワード予測1
-
好きと答えた理由を19(非飲食系:おいしそうを除く18)のイメージワードの出現割合で予測できます。膨大な自由回答から自然言語処理技術を駆使して構築しています。
- ・おいしそう(飲食系のみ)
- ・かわいい
- ・シンプル
- ・デザイン要素がよい
- ・なつかしい
- ・やさしい
- ・安心感・信頼感がある
- ・季節感
- ・健康感がある
- ・効果・効能を感じる
- ・高級感・上質感
- ・色味がよい
- ・新しい・ユニーク
- ・洗練
- ・爽やか・清涼感
- ・特徴がわかりやすい
- ・目立つ・印象に残る
- ・綺麗・美しい
- ・清潔
function 05イメージワード予測2
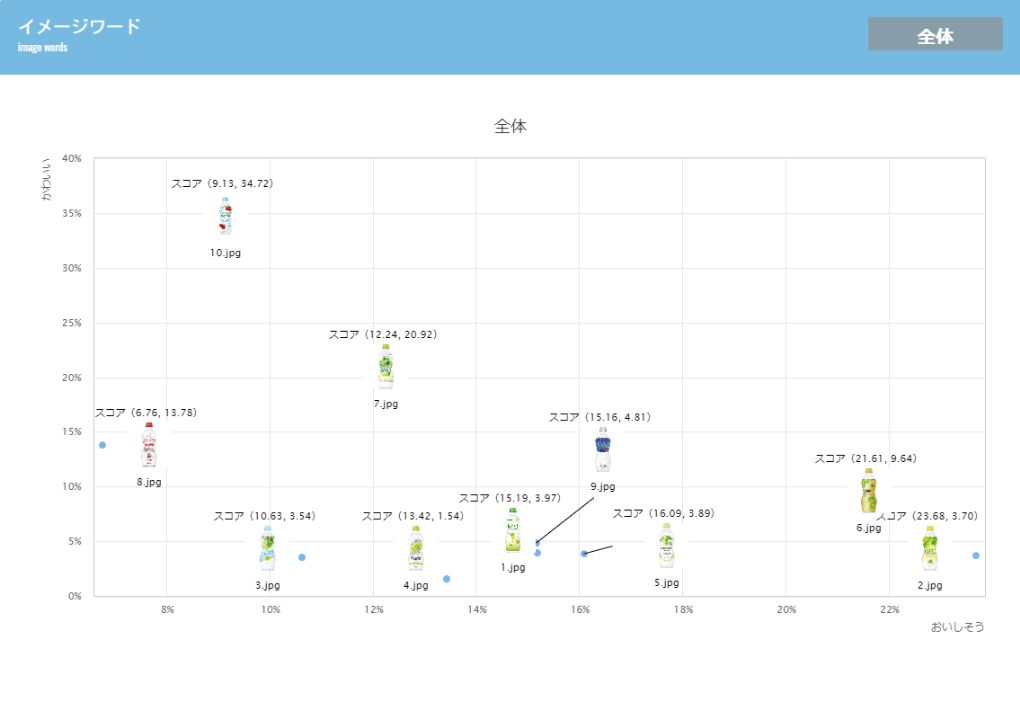
- 19のイメージワードのうち、2つのワードの組合せで画像のポジショニングマップを作成できます。コンセプトの重要ワードを比較することで、どちらに反応しているかが一目でわかります。
function 06好意度のバラツキ予測
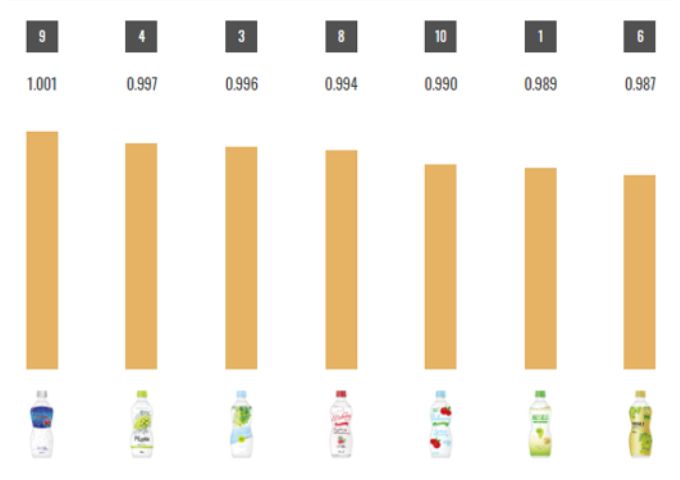
- 好意度の標準偏差(バラツキ)を予測します。数値が高いほどデザインの好き嫌いの差が大きいと解釈できます。 好意度スコアと一緒にみることで、万人に好まれるデザインか好き嫌いが大きいデザインか、がわかりやすく判断できますのでお勧めです。PDFとCSVで保存できます。
function 07一括レポート
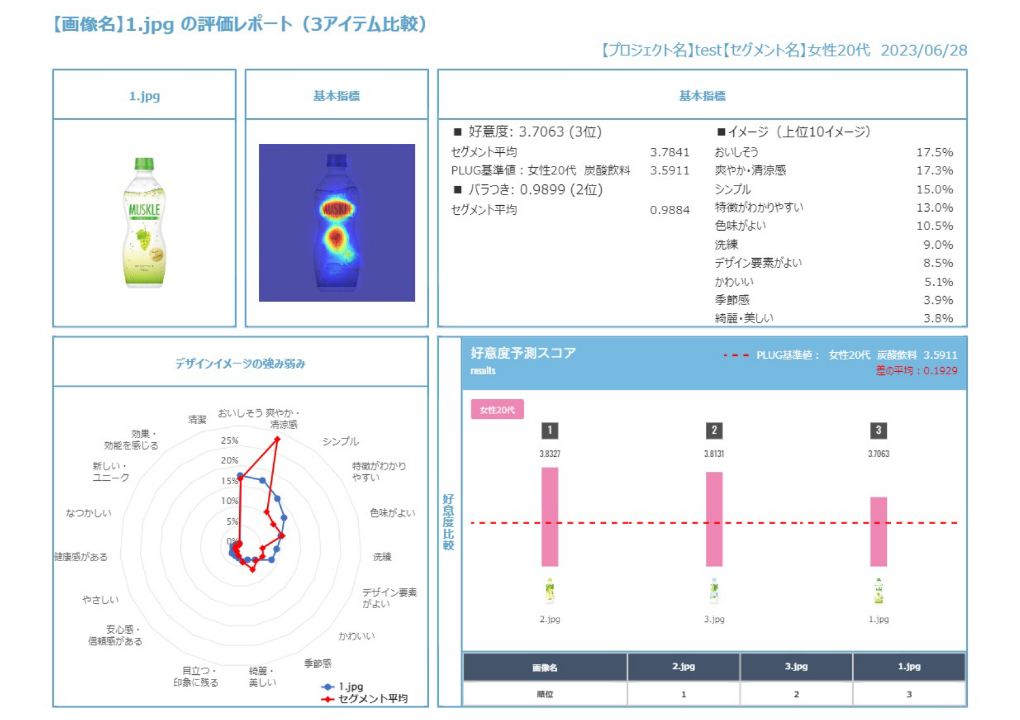
- セグメント・画像別に好意度、イメージワード、バラつき、ヒートマップの4つのメニューを1枚で整理して表示します。好意度やバラツキのランキング、基準値の入った好意度のグラフ、イメージワードTOP10やその強みと弱みのポジショニングマップといったデザインの意思決定における重要項目に絞ったレポートとなっています。
function 08商品棚のヒートマップ
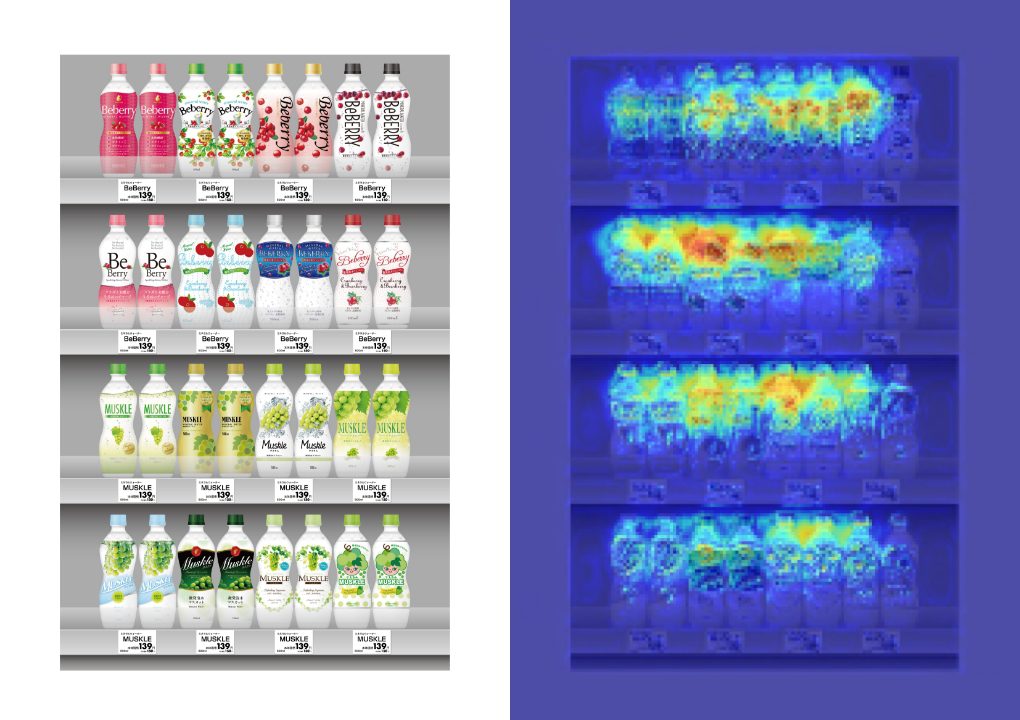
- 商品棚のどの個所が印象に残るかを可視化します。印象に残る割合が高いほど赤く、少ないほど青くなるように表示していますので棚の商品陳列で大切な指針となります。
function棚画像ヒートマップ
- 商品棚のどの個所が印象に残るかを可視化します。印象に残る割合が高いほど赤く、少ないほど青くなるように表示していますので棚の商品陳列で大切な指針となります。
function 01テキストからのデザイン生成
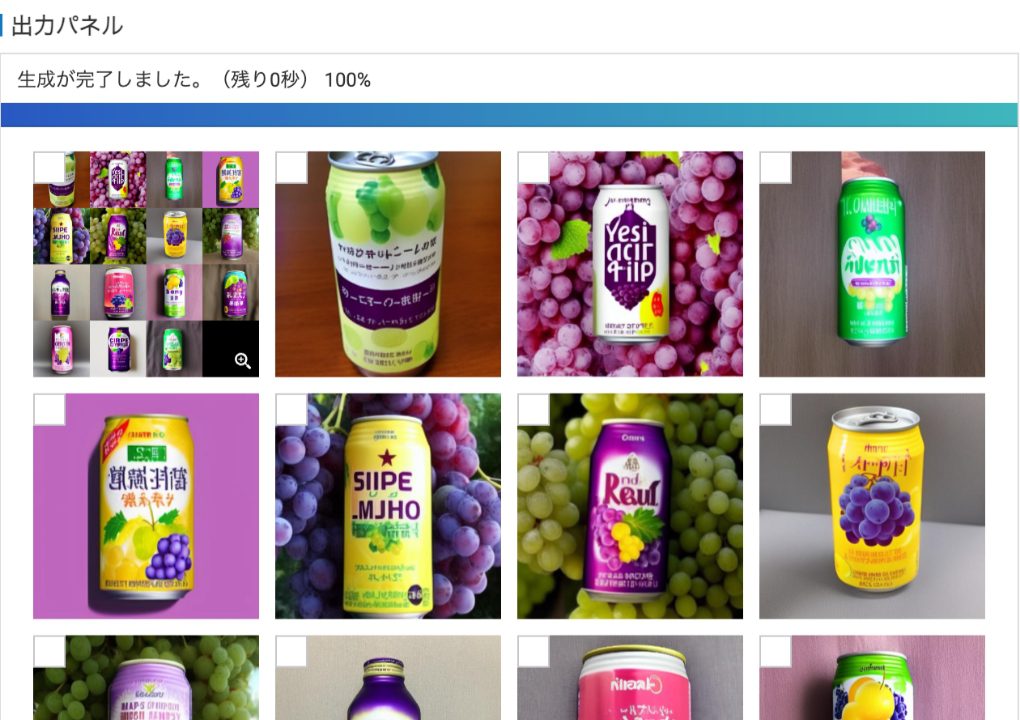
- 作りたいデザインのイメージやコンセプトを文字入力するだけで、その指示に沿ったデザイン案を生成します。文字は日本語対応です。生成時は、1回あたりの生成数や画像サイズ・学習回数をお好みで指定できます。
function 02画像とテキストからのデザイン生成

- アップロードする画像の基本的な構図を変えずに、入力したイメージに沿ったデザイン案を生成します。文字のみで生成した場合と比較して、目指す結果に対してより高精度に生成できます。
function 03画像の一部デザインを変更
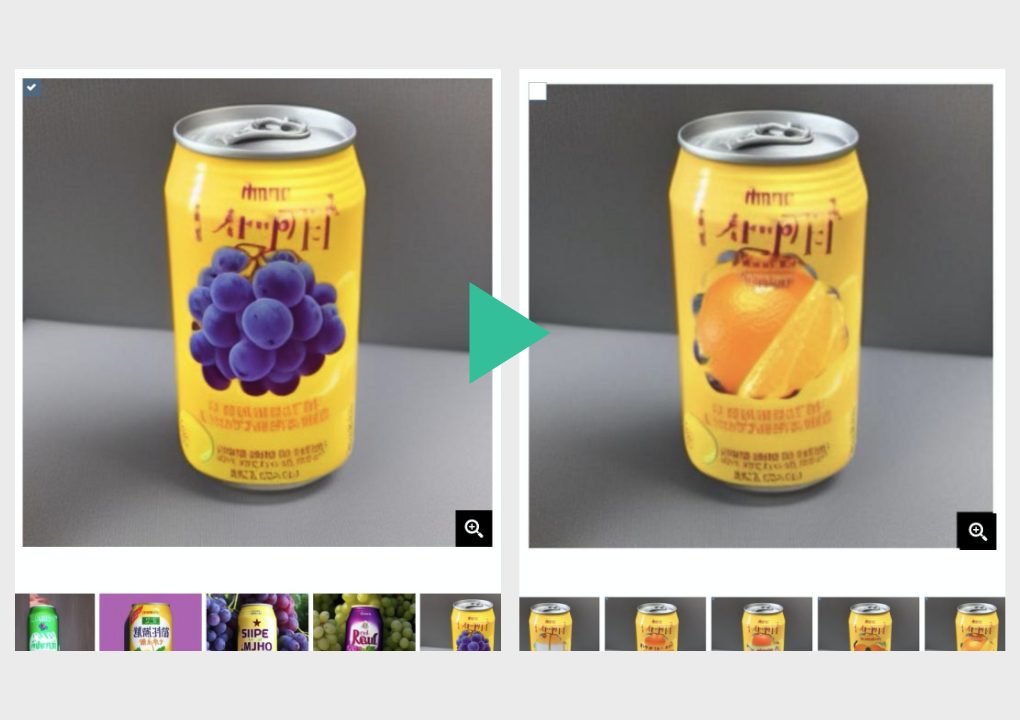
- アップロードする画像の一部のデザインをAIが再生成します。再生成する箇所は直接描画して指定します。商品ロゴだけ修正したいなど、特定の一部分を変更したいときに便利です。
function 04パッケージデザイン画像として保存

- 生成した画像は、画像単体あるいは一括でダウンロードできます(JPG形式、ZIP形式)。また、生成画像の背景を削除したうえでパッケージデザイン用画像として保存することもできます。
function 01ネーミング生成
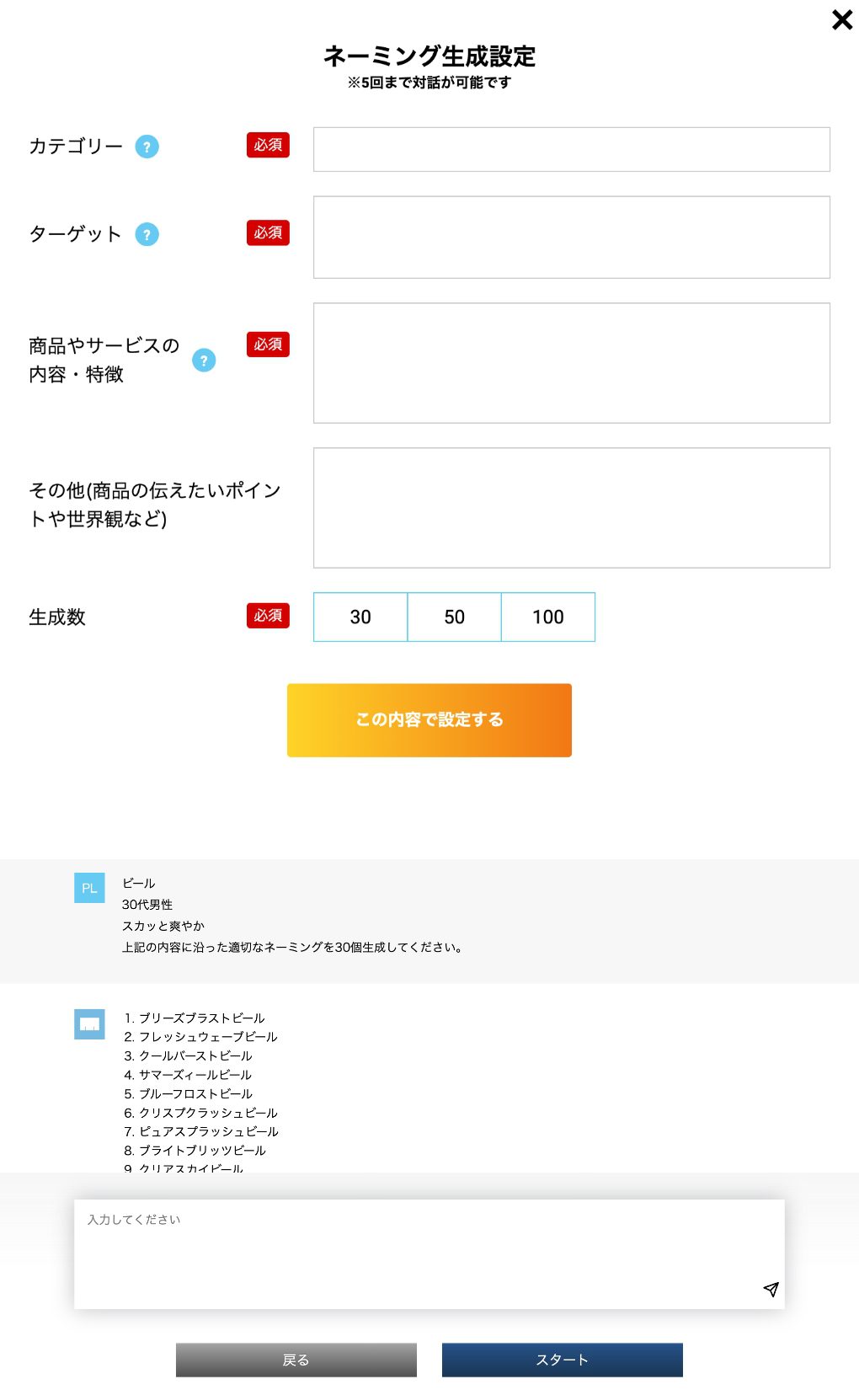
function 02キャッチコピー生成
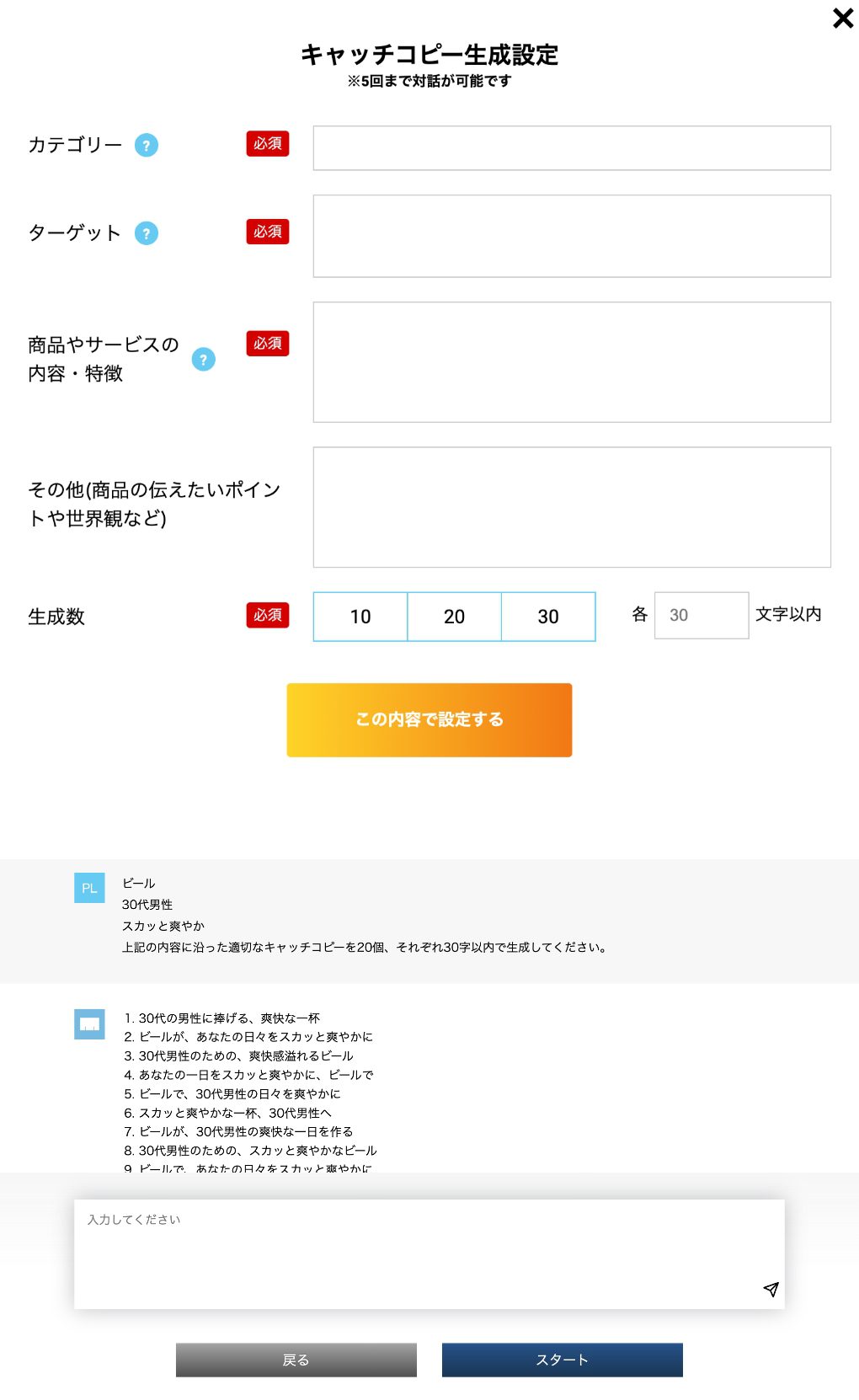
開発中の商品やサービスのカテゴリー、ターゲット、内容や特徴を入力するだけで、それに合致するネーミングやキャッコピーをAIが自動生成します。 生成結果は、対話方式で修正したり、深堀り・分析ができます。1プロジェクトあたり20回まで対話ができます。
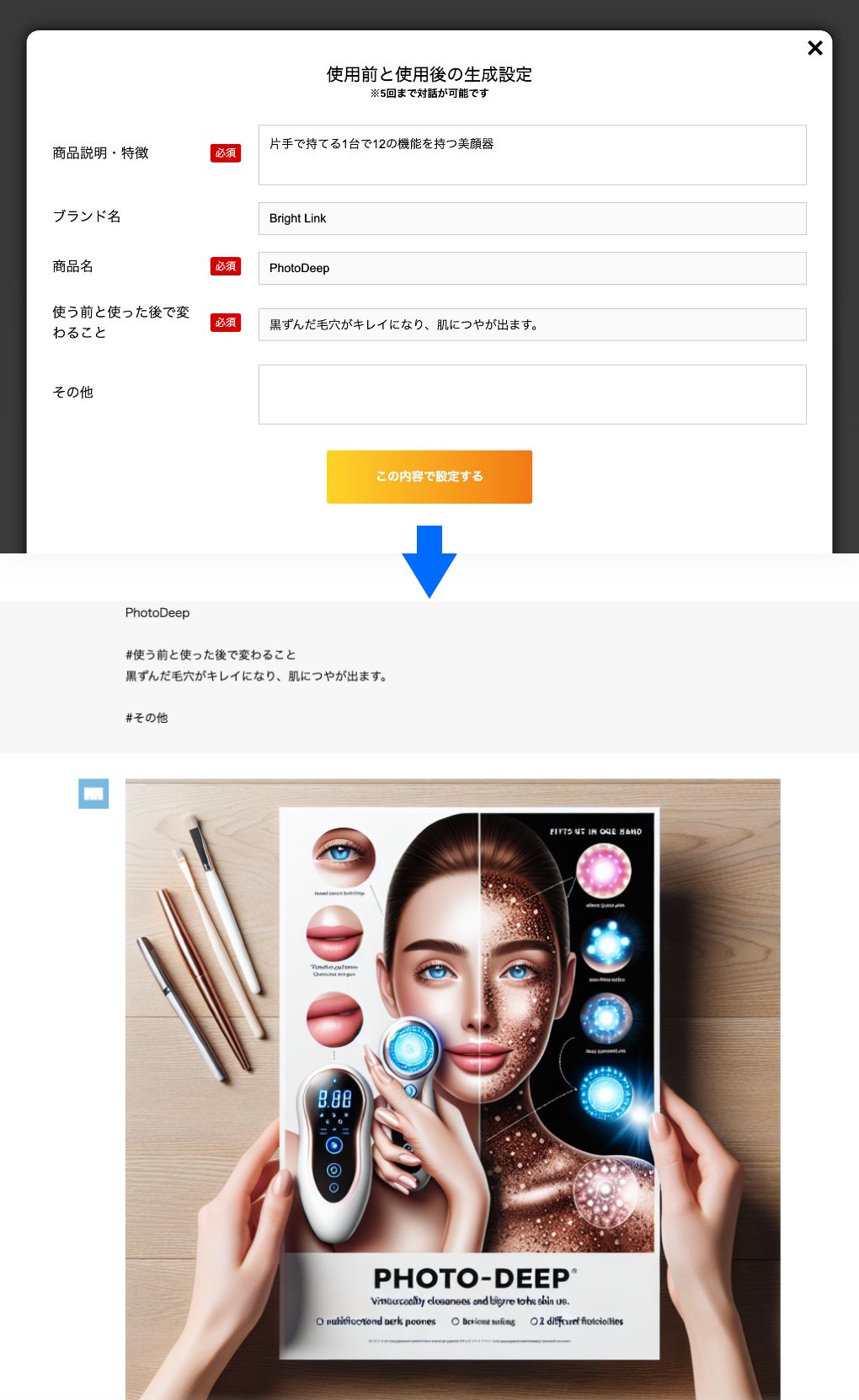
functionキービジュアル生成
「使用前と使用後」「困っているシーン」「ブランド世界観」など6テーマから、商品の特徴や伝えたいメッセージを入力するだけで、それに合致するキービジュアル画像(ポスター)をAIが自動生成します。 生成したデザインは、対話方式で修正したり、深堀り・分析ができます。1プロジェクトあたり20回まで対話ができます。